Finding Consensus
January 12, 2025
This project was inspired by consensus.app, an AI model designed to extract scientific consensus from present day research papers on yes/no questions. Where consensus.app narrowed its focus on science and black-and-white resolutions, I saw a clear gap to apply a similar approach, but to a more expansive and ambiguous space of such a major part of our present day discourse. Rather than simply extracting an affirmation or rejection from each piece of data, counting up the yes's and no's, and presenting that to the user, I looked to add more significant functionality which would allow me to capture and present a far more complex narrative: Looking for what a large collection of articles agree on, and, given a user's question, synthesizing that agreement into a useful answer that is probabilistically true.
Fundamentally, this project is an attempt to be a part of the iterative innovation needed to persist truth in a society that is decreasingly concerned about it. The sheer number of competing view points and rising tensions has clouded what we all agree on, even though common ground is a necessary foundation to positive discourse. If we're able to find it, the hope is that its recognition will create empathy for the opposing group(s).
The approach stems from a simple question—what do most sources, irrespective of their ideology, agree on? My approach is to extract recurrent claims, removing any bias or distortion associated with each to uncover shared claims. As an illustration, on the topic of Donald Trump's recent tariffs, the model output "President Donald Trump threatened the European Union with trade tariffs, and over the weekend, Trump announced 25% tariffs on Canada and Mexico.". This information was gathered from 185 recent articles (post 2025 inauguration) on Trump's trade policy that clearly demonstrate beyond partisan information. Although the scope of the model is currently quite limited due to the amount of training data that I have, this shows a promising beginning.
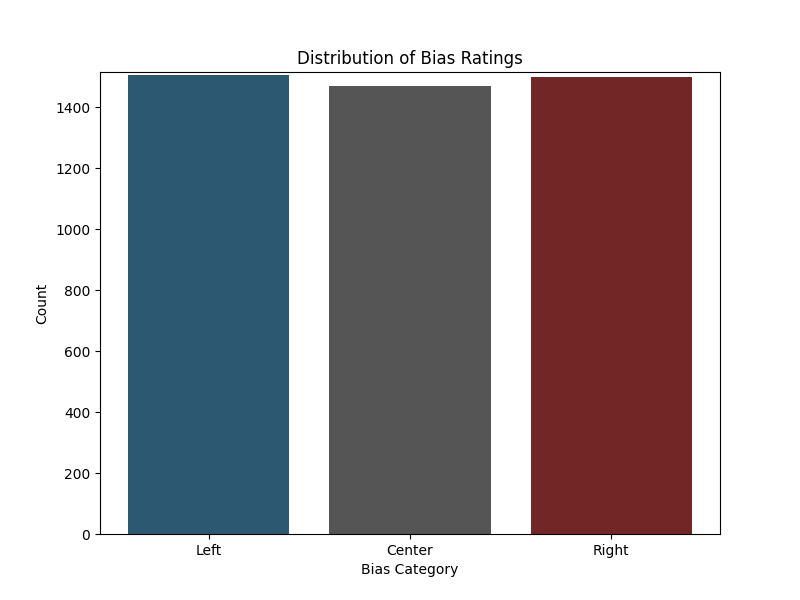
The project's technical backbone begins at APIs and RSS feeds that are used to obtain data from a wide range of sources. I've maticulously gathered a fair and even dataset to be extremely careful about introducing bias into the model. Bias ratings are gathered from https://mediabiasfactcheck.com/, a fantastic, non-partisan site, devoted to dispelling bias and ensuring accurate content delivery from news sources. I utilize this same dataset for my Mapping Bias in Journalism project too, so I am constantly updating and refining my dataset.
I then implement a multi-sage pipeline that starts by using BeautifulSoup to refine and clean data, spaCy and NTLK for text processing, and BERTopic which allows me to group articles based on their overarching themes. I then compute embeddings using SentenceTransformer which sets me up to run DBSCAN, a clustering algorithm that groups similar embeddings. Once that's complete, I use a deep learning-based text summarization model based on BART (a pre-trained transformer model) to get the final output. What finally emerges is my model of consensus, not a singular truth, but a framework to identify where information is at least widely acknowledged.
Of course, there are obvious downsides inherent to this model and it wouldn't be wise to not take them into account. Any system designed for the purpose of common ground runs the risk of confusing convergence with correctness. The question, "What if the consensus is wrong?", demonstrates an obvious pitfall. Thus far, my own review of the information has surfaced no inaccuracies which is an encouraging sign.
There are two approaches for the next stage of this project: widening the data and incorporating a greater volume of news sources or tightening the focus on a specific topic to get a set of core claims. It would certainly be interesting to see how a set of core claims would fair over time, so perhaps I will take it down that route. In any case, the adaptability of this largely automated pipeline is its strength. Truth itself is not always static, and as the space in which we consume information evolves, any tools built to augment it must evolve quickly too.
This project does attempt to dictate any narrative or claim objectivity where none exists. Instead, it aims to demonstrate the agreement of parties that are participating in an increasingly fragmented ecosystem. By meshing deep learning, psychology, and philosophy, I am attempting to provide a mechanism that would allow people to operate with more clarity.